Benutzerhandbuch
Inhalt
Version: 0.2 · Sprache: Deutsch
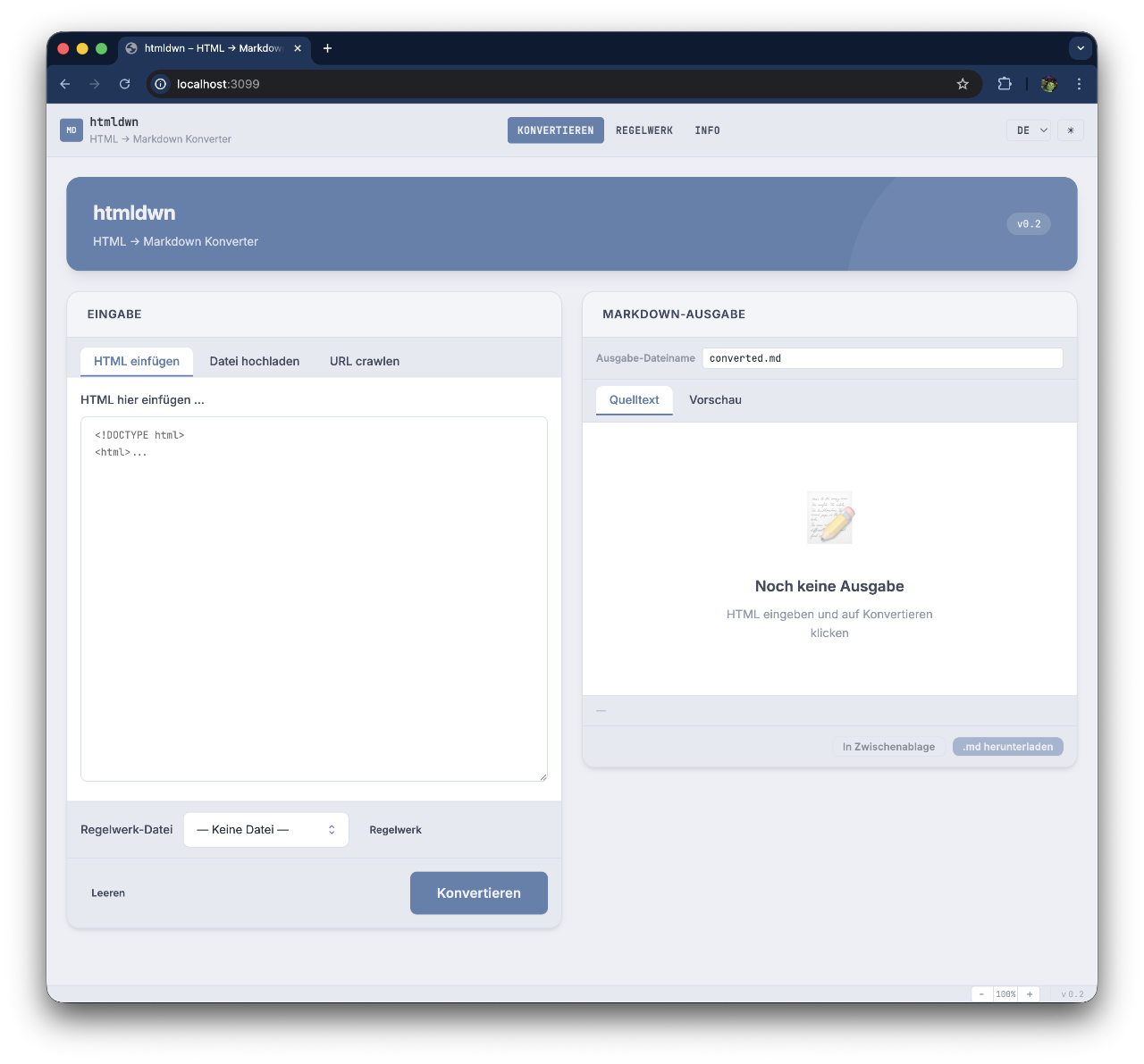
1. Was ist htmldwn?
htmldwn ist ein lokaler Web-Konverter, der HTML-Inhalte in sauberes Markdown (speziell GitHub Flavored Markdown / GFM ) umwandelt.
Die Anwendung läuft als kleiner Node.js-Webserver auf einem Rechner und ist über den Browser erreichbar. Sie benötigt keine Cloud-Anbindung und sendet keine Daten an Dritte.
Typische Anwendungsfälle:
- Alte Unternehmens- oder Dokumentationswebseiten in Markdown-Dateien umwandeln
- HTML-Seiten für statische Site-Generatoren (Hugo, Jekyll, Eleventy) aufbereiten
- Rohe HTML-E-Mails oder Word-Exporte bereinigen
- Massenkonvertierung von Legacy-Seiten (z. B. Microsoft FrontPage, Dreamweaver)
2. Voraussetzungen
Betriebssysteme
| Betriebssystem | Unterstützt | Hinweis |
|---|---|---|
| macOS (12 Monterey+) | ✅ | Empfohlen |
| Linux (Ubuntu 20.04+, Debian 11+, RHEL 8+) | ✅ | |
| Windows (10, 11) | ✅ | Über CMD oder PowerShell |
Laufzeitumgebung
| Software | Version | Empfohlen | Link |
|---|---|---|---|
| Node.js | 18.0.0+ | 20 LTS oder 22 LTS | nodejs.org |
| npm | 9.0.0+ | Wird mit Node.js mitgeliefert | — |
Node.js prüfen:
node --version # muss ≥ 18.0.0 sein npm --version # muss ≥ 9.0.0 sein
Netzwerk
- Der Server läuft lokal auf Port 3099
- Es wird keine Internetverbindung benötigt — außer beim URL-Crawl-Feature, das die angegebene Webseite direkt abruft
3. Installation
# 1. In das Projektverzeichnis wechseln
cd /pfad/zu/htmldwn
# 2. Abhängigkeiten installieren (nur einmalig nötig)
npm install
Nach npm install sind alle benötigten Bibliotheken im Ordner node_modules/
vorhanden. Das Verzeichnis wird nicht im Git-Repository gespeichert und muss
nach jedem frischen Klonen neu installiert werden.
4. Server starten
Schnellstart (alle Plattformen)
npm start
Der Server ist danach im Browser erreichbar:
http://localhost:3099
Startdateien (Doppelklick)
Im Projektverzeichnis liegen fertige Startdateien für alle Plattformen:
| Plattform | Datei | Hinweis |
|---|---|---|
| Windows | start.bat |
Doppelklick im Explorer |
| macOS | start.command |
Doppelklick im Finder (ggf. Ausführungsrecht setzen) |
| Linux | start.sh |
Terminal: bash start.sh |
macOS: Ausführungsrecht setzen (einmalig)
chmod +x start.command
Linux: Ausführungsrecht setzen (einmalig)
chmod +x start.sh
Entwicklungsmodus (Auto-Reload)
Für Entwickler steht ein Modus mit automatischem Neustart bei Dateiänderungen zur Verfügung:
npm run dev
Server beenden
Im Terminal: Strg + C (Windows/Linux) bzw. ⌃C (macOS)
4.2 Konfiguration (config.json)
im Projektverzeichnis liegt eine zentrale Konfigurationsdatei config.json.
Sie wird automatisch beim Serverstart geladen und kann ohne Codeänderungen
angepasst werden.
{
"server": {
"port": 3099,
"host": "localhost"
},
"app": {
"name": "htmldwn",
"version": "0.2"
},
"conversion": {
"maxHtmlSize": 10485760,
"maxUploadSize": 5242880,
"crawlTimeoutMs": 8000,
"crawlMaxResponseSize": 5242880
},
"rateLimit": {
"windowMs": 900000,
"maxRequests": 100,
"crawlWindowMs": 60000,
"crawlMaxRequests": 10
}
}
Parameter-Referenz
| Schlüssel | Typ | Standard | Bedeutung |
|---|---|---|---|
server.port |
Integer | 3099 |
TCP-Port, auf dem der Server lauscht |
server.host |
String | "localhost" |
Bind-Adresse (für lokalen Betrieb nicht ändern) |
app.name |
String | "htmldwn" |
Anwendungsname (über /api/config abrufbar) |
app.version |
String | "0.2" |
Versionsnummer (wird in der Statusleiste angezeigt) |
conversion.maxHtmlSize |
Integer (Bytes) | 10485760 |
Max. Größe von eingefügtem HTML (10 MB) |
conversion.maxUploadSize |
Integer (Bytes) | 5242880 |
Max. Größe von hochgeladenen Dateien (5 MB) |
conversion.crawlTimeoutMs |
Integer (ms) | 8000 |
HTTP-Timeout beim URL-Crawl (8 Sekunden) |
conversion.crawlMaxResponseSize |
Integer (Bytes) | 5242880 |
Max. Größe einer gecrawlten Seite (5 MB) |
rateLimit.windowMs |
Integer (ms) | 900000 |
Zeitfenster für Rate-Limiting (15 Min.) |
rateLimit.maxRequests |
Integer | 100 |
Max. Konvertierungen pro Zeitfenster |
rateLimit.crawlWindowMs |
Integer (ms) | 60000 |
Zeitfenster für Crawl-Rate-Limit (1 Min.) |
rateLimit.crawlMaxRequests |
Integer | 10 |
Max. Crawls pro Zeitfenster |
Port ändern (drei Möglichkeiten, in Prioritätsreihenfolge)
# 1. CLI-Argument (höchste Priorität)
node server/index.js --port 8080
# 2. Umgebungsvariable
PORT=8080 npm start
# 3. config.json (empfohlen für dauerhafte Änderung)
# server.port: 8080
5. Bedienung
Die Oberfläche besteht aus drei Bereichen (Navigation oben):
5.1 Konvertieren
Drei Eingabemethoden stehen zur Auswahl:
| Tab | Beschreibung |
|---|---|
| HTML einfügen | HTML-Code direkt in das Textfeld einfügen |
| Datei hochladen | Eine .html- oder .htm-Datei vom Rechner wählen |
| URL crawlen | Eine Web-URL angeben; htmldwn lädt die Seite herunter |
Nach der Konvertierung erscheint das Ergebnis rechts:
| Ansicht | Beschreibung |
|---|---|
| Quelltext | Das fertige Markdown — direkt bearbeitbar |
| Vorschau | Gerenderte Darstellung (zur schnellen Kontrolle) |
Die Ausgabe kann heruntergeladen (.md-Datei) oder in die Zwischenablage
kopiert werden. Der Dateiname wird automatisch aus der Quell-URL oder dem
Dateinamen abgeleitet und kann vor dem Download manuell geändert werden.
5.2 Quelltext bearbeiten
Nach der Konvertierung ist der Quelltext direkt in der Eingabefläche bearbeitbar — ähnlich einem einfachen Texteditor:
- Tippen, löschen, einfügen funktioniert wie erwartet
- Wechsel zur Vorschau zeigt sofort den aktuellen (bearbeiteten) Stand
- Herunterladen und In Zwischenablage übernehmen automatisch den bearbeiteten Text — nicht den ursprünglichen Konversionsergebnis
- Die Höhe des Editors lässt sich durch Ziehen der unteren rechten Ecke anpassen
- Eine neue Konvertierung überschreibt den aktuellen Editorinhalt
Tipp: Kleine manuelle Nacharbeiten (z. B. Formatierung, Titelzeilen, Frontmatter) können direkt hier erledigt werden, bevor die Datei gespeichert wird.
5.3 Regelwerk
Hier werden benutzerdefinierte Konvertierungsregeln verwaltet. Eine gespeicherte Regel-Datei kann aus dem Dropdown ausgewählt werden — sie wird sofort geladen und alle Regeln erscheinen in der Liste.
6. Das Regelwerk
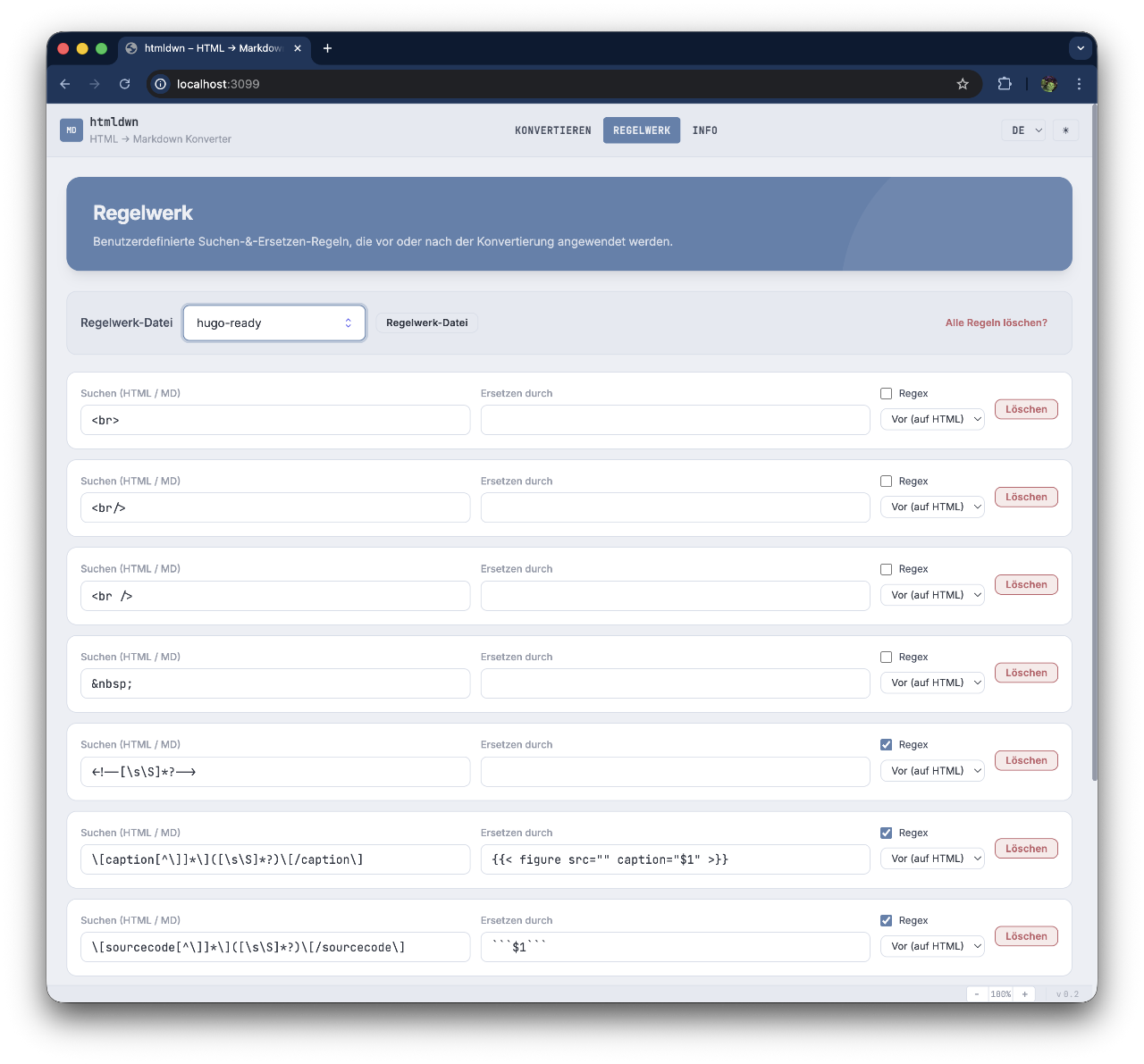
Das Regelwerk ist das Herzstück von htmldwn für anspruchsvolle Konvertierungen. Es erlaubt, den HTML-Quelltext vor der Konvertierung und das fertige Markdown nach der Konvertierung durch Suchen-&-Ersetzen-Regeln zu bereinigen.
Funktionsprinzip
Die Konvertierungs-Pipeline läuft in dieser Reihenfolge:
HTML-Quelle
│
▼
[0] Cheerio HTML-Vorverarbeitung (automatisch, immer aktiv)
│ - Layout-Tabellen erkennen und plattmachen
│ - FrontPage-Kommentare entfernen
│ - Spacer-Bilder entfernen
│ - Tabellen ohne Kopfzeile: erste Zeile wird Header
│
▼
[1] Pre-Regeln aus dem Regelwerk (auf den HTML-String angewendet)
│ → Suchen & Ersetzen im HTML, bevor Turndown konvertiert
│
▼
[2] Turndown-Konvertierung (HTML → Markdown)
│ - Eingebettete Regeln: <pre>/<code> → Backticks
│ - <strong>/<b> → **text** (direkt am Text)
│ - GFM-Tabellen, Listen, Überschriften, Links …
│
▼
[3] Post-Regeln aus dem Regelwerk (auf den Markdown-String angewendet)
│ → Suchen & Ersetzen im fertigen Markdown
│
▼
[4] Markdown-Ausgabe
Aufbau einer Regel (JSON)
Jede Regel ist ein JSON-Objekt mit diesen Feldern:
{
"description": "Kurze Beschreibung was die Regel macht",
"search": "zu suchender Text oder Regex-Muster",
"replace": "Ersetzungstext",
"isRegex": true,
"mode": "pre"
}
| Feld | Typ | Beschreibung |
|---|---|---|
description |
String | Erklärender Text (nur zur Dokumentation, hat keine Funktion) |
search |
String | Suchbegriff — bei isRegex: true ein regulärer Ausdruck |
replace |
String | Ersetzungstext; bei Regex: $1, $2 … für Gruppen |
isRegex |
Boolean | true = Regex-Muster, false = exakter Textvergleich |
mode |
String | "pre" = auf HTML, "post" = auf Markdown, "both" = beides |
Regex-Grundlagen für Regeln
Häufig verwendete Regex-Muster:
| Muster | Bedeutung | Beispiel |
|---|---|---|
. |
Beliebiges Zeichen | colou.r → color, colour |
* |
0 oder mehr des vorherigen | ab*c → ac, abc, abbc |
+ |
1 oder mehr des vorherigen | ab+c → abc, abbc |
? |
0 oder 1 des vorherigen | colou?r → color, colour |
[^<\n] |
Kein < und kein Zeilenumbruch |
Einzeiligen Text matchen |
[\s\S]*? |
Beliebiger Text inkl. Zeilenumbrüche (nicht-gierig) | Mehrzeilige Blöcke |
$1, $2 |
Capture-Gruppen in replace |
Gefangenen Text wiederverwenden |
Wichtig bei JSON-Regelwerken: Backslashes müssen doppelt geschrieben werden:
\\sstatt\s,\\nstatt\nusw.
Beispielregeln
<font>-Tags entfernen (Inhalt behalten)
{
"description": "font-Tags entfernen",
"search": "<font[^>]*>",
"replace": "",
"isRegex": true,
"mode": "pre"
}
→ normales Leerzeichen
{
"description": "Non-breaking Space normalisieren",
"search": " ",
"replace": " ",
"isRegex": false,
"mode": "pre"
}
Mehrfache Leerzeilen auf zwei reduzieren (Post-Rule)
{
"description": "Mehrfache Leerzeilen normalisieren",
"search": "\\n{3,}",
"replace": "\n\n",
"isRegex": true,
"mode": "post"
}
WordPress-Shortcodes entfernen (Post-Rule)
{
"description": "WordPress Shortcodes [caption ...] entfernen",
"search": "\\[/?[a-zA-Z_-]+[^\\]]*\\]",
"replace": "",
"isRegex": true,
"mode": "post"
}
Regelwerke speichern und laden
Regeln können über die Regelwerk-Seite in einer JSON-Datei im
rules/-Verzeichnis gespeichert werden. Der Dateiname muss auf .json enden.
Gespeicherte Dateien erscheinen automatisch im Dropdown der Konvertierseite
und können dort ausgewählt werden.
7. Verfügbare Regelwerke
Im Verzeichnis rules/ liegen vier vorgefertigte Regelwerke:
default.json — Universelle Basis
Empfohlen als Grundlage für alle Konvertierungen. Enthält:
<br>-Varianten → Markdown-Zeilenumbruch → Leerzeichen- HTML-Kommentare entfernen
- Post-Sicherheitsnetze für
<code>,<pre>,<strong>,<b> - Whitespace-Normalisierung
legacy-frontpage.json — Allgemeines 90er/2000er HTML
Breiteres Netz für alle Seiten des FrontPage/Dreamweaver-Zeitalters:
- Zusätzlich:
<center>,<b>/<i>normalisieren - Bullet-Bilder aus FrontPage-Themes entfernen
- Horizontale Trennlinien als Markdown-HR
hugo-ready.json — Hugo-CMS-Vorbereitung
Für Seiten, die nach Hugo migriert werden:
- WordPress-Shortcodes entfernen
- Hugo-spezifische Bereinigungen
8. Grenzen & bekannte Einschränkungen
⚠️ Was nicht oder nur eingeschränkt funktioniert
JavaScript-gerenderte Inhalte
Seiten, die ihren Inhalt erst durch JavaScript aufbauen (React, Angular, Vue, Single-Page-Apps), können nicht gecrawlt werden. htmldwn ruft nur den statischen HTML-Quelltext ab — was der Browser zur Laufzeit rendert, ist nicht sichtbar. Lösung: In solchen Fällen den HTML-Quelltext manuell aus dem Browser-DevTools kopieren und über „HTML einfügen" einsetzen.
CSS-Formatierung geht verloren
Farben, Schriftgrößen, Abstände und alle visuellen Stile werden nicht übertragen. Markdown kennt keine CSS-Formatierung. Nur Struktur und Semantik (Überschriften, Listen, Fett/Kursiv, Tabellen, Links) bleiben erhalten.
Komplexe verschachtelte Tabellen
Tief verschachtelte Tabellen-in-Tabellen-Strukturen werden nur begrenzt
korrekt verarbeitet. Layout-Tabellen (ohne <th>) werden automatisch
geplättet — dabei kann bei sehr komplexen Strukturen Inhaltsreihenfolge
verloren gehen. Datentabellen werden korrekt als GFM-Tabellen ausgegeben.
Bilder
Bilder werden als Markdown-Bildlinks übernommen: . Relative
Bildpfade (z. B. ../images/foto.jpg) bleiben relativ und sind nach der
Migration möglicherweise ungültig. Die Bilddateien selbst werden nicht
heruntergeladen.
Formulare und interaktive Elemente
<form>, <input>, <button>, <select> werden vollständig entfernt.
Markdown hat kein Konzept für Formulare.
Iframes
<iframe>-Inhalte werden entfernt. Der eingebettete Inhalt (z. B. YouTube-
Videos, Karten) ist nicht zugänglich.
Sehr große Seiten
Der Crawler akzeptiert maximal 5 MB pro Seite. Für lokale Datei-Uploads gilt dieselbe Grenze. Größere Dateien müssen aufgeteilt werden.
Timeout beim Crawlen
Der Crawler wartet maximal 8 Sekunden auf eine Antwort. Langsame Server oder Seiten mit großen Ressourcen können einen Timeout auslösen.
Passwortgeschützte Seiten
Der Crawler kann sich nicht authentifizieren. Seiten hinter Login-Masken, Basic Auth oder IP-Sperren sind nicht zugänglich.
Zeichenkodierung
Die meisten Verzeichnisse werden korrekt erkannt (UTF-8, ISO-8859-1, Windows-1252). Bei seltenen oder alten Zeichensätzen (z. B. ISO-2022-JP, EBCDIC) kann es zu Darstellungsfehlern kommen.
SVG und MathML
SVG-Grafiken und mathematische Formeln (MathML) werden entfernt.
Tabellen ohne semantischen Header
Tabellen, bei denen alle Zeilen rein strukturell gleichwertig sind (keine inhaltlich ausgezeichnete Kopfzeile), werden mit der ersten Zeile als Header ausgegeben. Das ist technisch korrekt aber inhaltlich möglicherweise ungenau — in diesem Fall die erste Zeile manuell anpassen.
9. Sicherheitshinweise
htmldwn ist für den lokalen Einsatz konzipiert. Folgende Sicherheitsmaßnahmen sind eingebaut:
- Rate Limiting: Konvertierungen sind auf 100 Anfragen / 15 Minuten begrenzt; Crawl-Anfragen auf 20 / 15 Minuten
- SSRF-Schutz: Crawl-Anfragen an private IP-Adressen (localhost, 192.168.x.x, 10.x.x.x usw.) werden blockiert
- Datei-Typ-Validierung: Nur
.html- und.htm-Dateien werden akzeptiert - Pfad-Traversal-Schutz: Regelwerk-Dateinamen werden validiert
- Helmet: HTTP-Sicherheits-Header sind gesetzt
⚠️ htmldwn sollte nicht ohne weitere Absicherung im öffentlichen Internet betrieben werden. Für Team-Einsatz empfiehlt sich ein VPN oder Reverse Proxy mit Authentifizierung.
htmldwn v0.2